DQN及其改进算法实现
具体相关代码实现在个人github上
1. 强化学习平台 gym 平台
gym的主要是一个提供小游戏来进行强化学习,其通过返回state给强化学习Agent来选择action并对于action返回相应的reward给Agent来学习最佳策略。
本次实验中用到的gym环境是LunarLander-v2,其具体信息在此
2. DQN介绍
q-learning的缺点之一在于对于状态空间庞大,或是action过多时,建立的Q表也将极其庞大,为了解决这个问题,可以使用神经网络来代替查表过程,通过state输入获得各个action的Q值输出即如图所示

在gym的LunarLander实验中有两种形式,一种是本实验采用的状态不是连续的LunarLander-v2,其状态空间由8个值组成,可选动作有4个,故可采取4层网络来搭建输入层为8个神经元构成的state,两层隐藏层都为64个单元构成,最后一层输出层为每个动作对应的Q值,也就是4个单元组成。另一种形式是LunarLanderContinuous-v2,与前一种的区别在于其动作由两个连续的值来控制一个控制油门,另一个控制左右引擎,可以通过离散化的方法来将其转化为前一种形式从而使其能够被q-learning处理,其处理思想可以参考这里。
q-learning缺点之二在对于样本状态具有连续性时,从而使得学习到“经验”并不具有代表性。而DQN采取两种做法来避免这个问题。其一,是利用一个“经验池”来存取多场游戏所获得的轨迹信息,而在学习的过程中采取随机抽取的方式来避免相关性问题。其二,是引入另一个Target网络来延缓Q值更新,从而减小了不断更新的Q值(令为Eval网络获得的)和隔一段时间更新一次的Target网络的Q值的相关性。
3. DQN算法流程
图一为论文Human-level control through deep reinforcement的算法实现,图二为其图解流程图

图一 论文算法实现
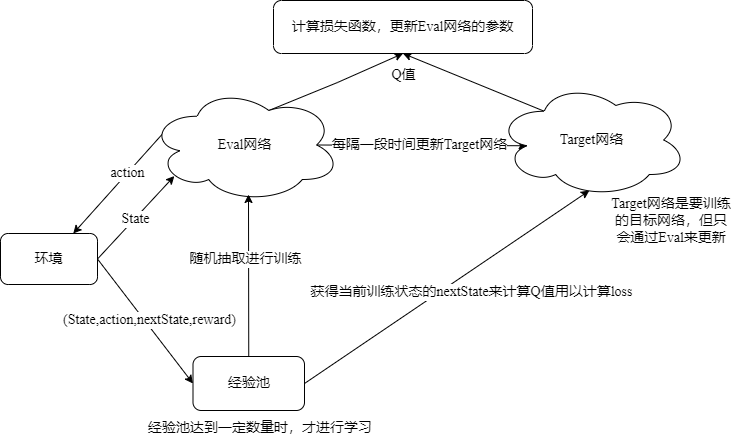
图二 算法图解流程
4. 基于DQN的算法改进
4.1 Double DQN
4.1.1 问题提出
DQN在算法实现中,其Q值计算需要根据其nextState的Q值来估算当前的Q值,而在训练过程中所选的nextState是通过比较它们之间Q值来最终选取的,虽然在最终成品上也是选取Q值最大的状态作为nextState,但在实际训练中,由于所有状态的Q值都需要初始化,所以如果仅比较Q值可能只是对于那些已经训练过的状态有利。
4.1.2 算法原理
Double DQN的做法是利用两个网络来解决,利用一个网络计算Q值来选取Q值最大所对应的action,而另一个网络来获得该action所对应的Q值。刚好可以对应于上述DQN算法的Eval网络和Target网络,便可以利用不断更新的Eval网络来获得实时的、“最好”的action,而利用目标Target网络来获得其Q值,因为Target网络存在延迟性,故可以延缓Q值最大的更新速度,或是避免最优action在训练初期Q值很小,从而在后期被丢弃。从而平滑整个训练过程。
其算法实现也仅仅是改变了在计算Target网络的Q值时将本来的maxQ(Target_action)改成了从Eval网络得到的action所对应Target的Q(Eval_actoin)而已
4.2 Dueling DQN
4.2.1 问题提出
可用于解决当有多个action的Q值相似时,不知选取哪个作为该状态的对应动作。
4.2.2 算法原理
Dueling DQN其原理是改变DQN的网络结构,它将State输入用于两个网络,一个作为Value function其与当前要选择的动作造成的影响无关(记作V(s)),其更考虑未来的情况所造成的影响。另一个作为advantage function用来关注当前的状态情况(记作Q(s,a))。其在论文《Dueling Network Architectures for Deep Reinforcement Learning》中如图三所示,整个网络的结构如图四所示。

图三 两个函数不同的关注重点
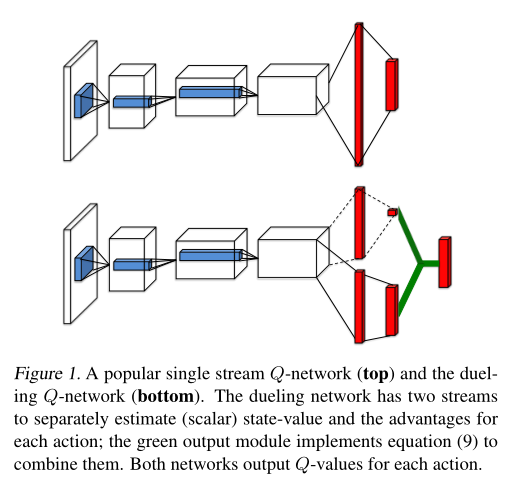
图四 Dueling DQN网络结构
在DQN中其网络的输出为Q(s,a)代表着当前状态和动作对结果的影响程度,越大代表每条策略经过它的可能性越大。论文中给出如下关系Q(s,a) = V(s)+A(s,a)。其原理就是让原来仅以一个网络获得Q(s,a)变成利用两个网络来相互制衡获得Q(s,a)。但在实际过程中,Q(s,a)很大程度要依赖V(s)的值,而整个训练过程,V(s)的值可能为0,即A(s,a)=Q(s,a)这与实际不符。故可以对A(s,a)进行约束,如另整个等式为Q(s,a) = V(s)+(A(s,a)-mean(A(s,a)))